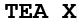Morse Code: Commentary |
Description of the Program
The program is a system that converts between plaintext and Morse code.
Plain text is language printed alphabetically (A, B, C, etc.), whereas Morse code uses patterns of dots and dashes to represent each letter in the alphabet:
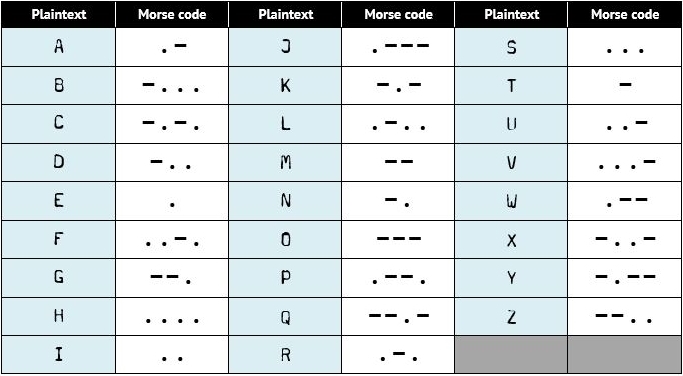
Each character is separated by a space, so the word HELLO is represented as follows:

Included within the pre-release material is a text file called ‘message.txt’. The contents of this file are as follows:

Note: The ⌂ symbols are not included in the text file, they have been included in these notes to represent spaces, to make them more visible for this explanation. The message.txt file consists of spaces and equals symbols only.
Overview
The program has two subroutines that handle conversion between plaintext and Morse code:
ReceiveMorseCode
The subroutine ReceiveMorseCode reads Morse code from a text file and converts it to plain text. One of the key subroutines used to perform this conversion is Decode. The subroutine SendMorseCode takes plaintext from the user at the keyboard and converts it to Morse code.
ReceiveMorseCode consists of three main stages:
- Extract text from a file. The file contains only spaces and equals symbols. A single equals (=) makes a dot. Three in a row (===) make a dash. Below is an extract from the text file:
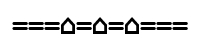
- Convert the series of equals symbols to a series of dots and dashes. The sequence in the box above would become:
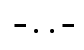
- Convert the series of dots and dashes to plaintext, which is a letter between A and Z. The pattern in the box above would become:
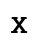
This process is repeated until the entire message has been translated into plaintext, at which point it is displayed in the console.
SendMorseCode
SendMorseCode is less involved. The user types uppercase plaintext at the console, which is converted into Morse code. The Morse code is then displayed on the console. Any spaces in the plaintext are represented as three spaces in Morse code.

ReceiveMorseCode Subroutine
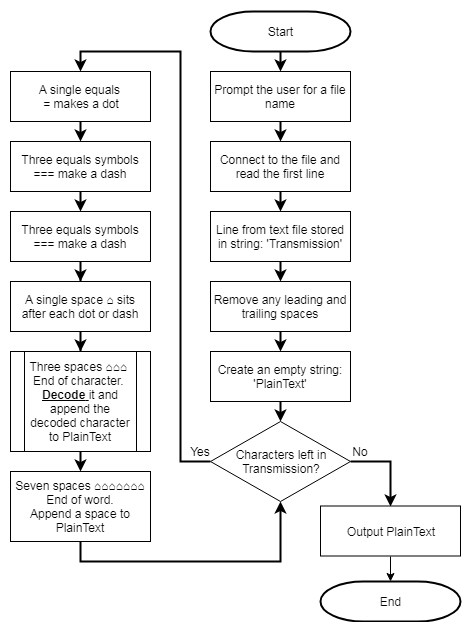
ReceiveMorseCode calls seven other subroutines, either directly or indirectly. These calls are not all included in the flowchart, as the flowchart exists only to provide a top-level understanding of the program.
Decode Subroutine
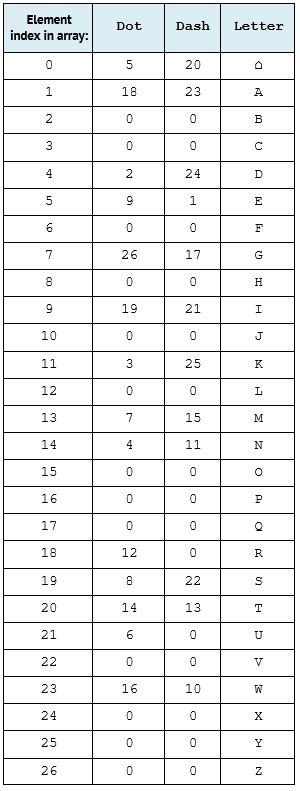
The subroutine Decode uses three lists in parallel; Dot, Dash and Letter, whose contents remain the same throughout execution.
The flowchart below shows how Decode would translate the pattern -.- into the plaintext character ‘K’:

If the first character is a dash (-), the program starts by looking at index 0 in the Dash list. If the first character is a dot (.), the starting point is index 0 of the Dot list.
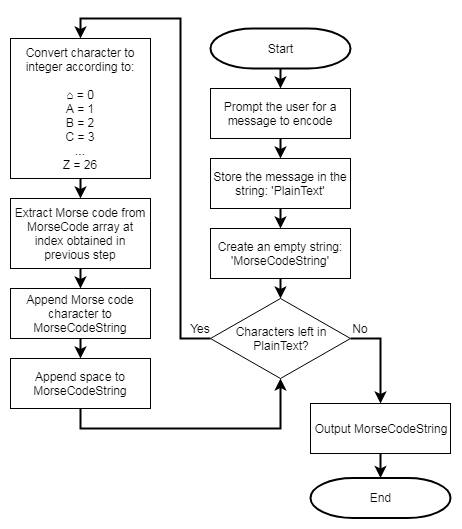
SendMorseCode Subroutine
Unlike ReceiveMorseCode, which calls several other subroutines, SendMorseCode is self-contained, and calls no other subroutines.
The user enters a message, which is validated to ensure it contains only upper-case characters and spaces.
The message is then translated, one character at-a-time, using Morse code equivalents taken from a list called MorseCode.
The Text File (message.txt)
The contents of the text file are explained below:
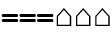 | This is a dash (===), followed by three spaces. Three spaces signals the end of a character, but not the end of a word. The character that is made up of a single dash is the letter T. |
 | This is the second character, which is a single dot, making it the letter E. |
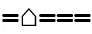 | This character is a dot followed by a dash. A single space is used between them (instead of three spaces), because the character is not finished yet. The Morse code comprising a dot followed by a dash is for the letter A. |
 | This is then followed by seven spaces, which are used to form a gap between two words. |
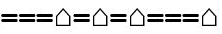 | This is a character that is made up of a dash, followed by a dot, followed by a dot, followed by a dash, which make up the letter X. |
The whole message, therefore, is: